back in june 2022, i started working on what would become skowt.cc (formerly wanderer.moe). i was still very new to webdev at the time. i had a personal website written in plain html, css and js, and hosted a temporary file uploader i wrote with flask. so the overall experience has been truly a learning curve.
## old "architecture"
the website's old stack wasn't very good for a lot of reasons. the API was solely just indexing from an r2 bucket for assets. literally just listing files from object storage and calling it a day.
here's an example of how the old storage was organized:
everything was manually mapped from slug to actual display name, hardcoded in the frontend. every. single. mapping. it was maintainability hell.
i also faced a very peculiar issue with our old api setup where not all the games would show at the root, so they had to be hard-coded, which was far from ideal.
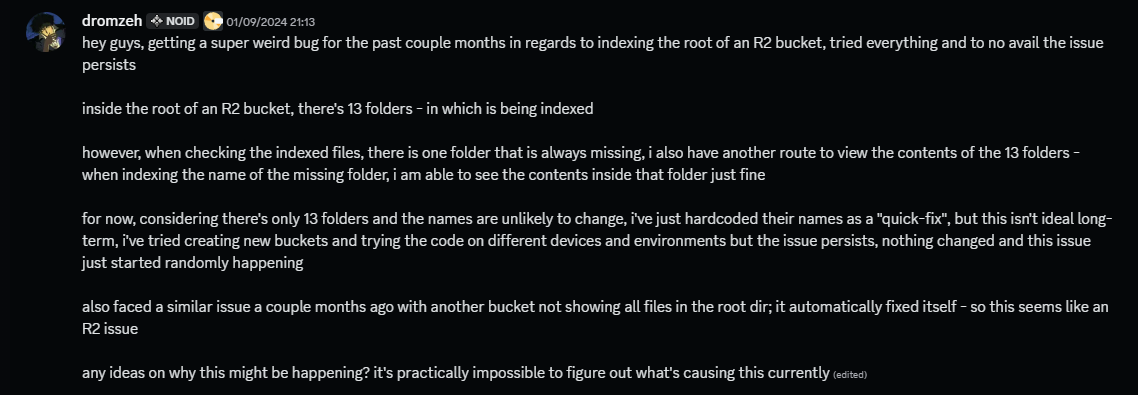
## expenses & caching nightmare
another issue with this is that it was very expensive. cloudflare charges around $4.50 per million class A requests (writes/lists), and $0.36 per million class B requests (reads). when you're serving 300k+ users, those list operations add up fast.
this meant that incredibly heavy and strict caching had to be placed on the site at all times to keep costs low. we're talking:
- 1 week cache on game lists
- 24 hour cache on [game] and [game]/[category] pages
- messy cloudflare page rules everywhere
with such heavy caching as we previously had, you run into issues all the time. users reporting bugs that were already fixed. new assets not showing up. my dms on fire. it was just an overall nightmare to handle or fix, because of said caching.
## the old upload "pipeline"
with the old r2 setup uploading files worked via the entire bucket being on a github repo (yes, you read that right). every single asset. in. a. github. repo.
once changes were pushed, a workflow would run that would sync the repository's contents with the r2 bucket itself. this, again, was:
- slow (20-30 minute deploys, even worse with the caching)
- very expensive (every sync = thousands of write operations)
- contributor hostile (who is really submitting prs for adding assets)
because of this - assets on the site weren't really updated at all, it was just way too expensive and painful.
## mid 2023: the "rewrite" begins
back in mid 2023, when skowt exploded in popularity and was at its peak, i announced that i was planning on updating the site and moving away from our previous infrastructure. the site had grown to hundreds of thousands of monthly active users. it wasn't just a side project anymore.
i started looking into databases really early in mid 2023, and went through loads until i settled with turso, which i pretty much use for all my projects now. it's libsql (sqlite fork), which works perfect.
skowt's "v2" api was rewrote a lot during this time, but then i just went too ott. i was planning on adding like oc generators and stuff - basically turning it into this massive platform instead of just fixing the core issues. classic scope creep.
so, that's where originoid came from - all those ideas that were too much for skowt became their own thing. originoid was first announced in october 2023.
## burnout era
and then... burnout.
i was scared to release stuff, didn't believe in myself with the burnout and just became overall scared to work on it. everything was delayed, and delayed, and delayed. with how popular it is, the only real thing on your mind is pleasing your users.
i was demotivated to work on skowt as i lost passion and interest for it alongside no longer being active surrounding the community of the games it supported. but here's the thing - it's a massive project, with hundreds of thousands of mau. it's not just a project i could let die.
the site was kept in a "minimal" state, meaning there was no real major updates, and there was just complete silence until may 2024, where i had to rewrite the entire site in just a couple hours to nextjs due to a ddos, as i hadn't touched sveltekit (the old framework) in so long, rewriting was the best option to solve the issues.
after the rewrite, i officially announced i would be keeping the site in a "maintenance updates only" mode, and also took many long breaks during this time, my mental health surrounding the project also impacted this.
## july 2025
then came july of this year. as i've been working more and more on originoid before release, i decided to go back to skowt. as originoid also uses libsql (turso) and hono for its backend, it felt way easier to get it out the way with the knowledge i've gathered from originoid.
i also thought about how to take the load off myself, which came to allowing the contributors in our discord to upload assets directly to the site instead of relying on me to upload it for them.
## the migration
the migration was done via hacky typescript scripts and raw sql. it looked a little something like this:
(no, that is not my PC making that noise, that is my fan. uk weather is lethal)
### how the migration actually worked
the transformation from indexing via r2 to a proper relational database was... interesting. here's what the scripts had to do:
phase 1: asset migration
- scan through every game folder in r2
- for each game, create a database entry with proper uuid (using uuidv7 for sortable ids)
- scan each category folder within games
- for every asset file found:
- calculate sha256 hash (for deduplication)
- extract file metadata (size, creation date)
- generate new uuid-based filename
- copy to new flat structure:
/assets/{uuid}.{ext} - insert into database with all relationships
phase 2: game-category relationships
since games can have different categories, i needed to build a many-to-many relationship table. this isn't really needed, but i implemented it becuase with the new search, it allows for users to understand if categories exist for certain games, etc, easily. so, the script did the following:
- mapped all existing folder structures to game-category pairs
- created junction table entries
- deduplicated (because the old structure had duplicates everywhere)
phase 3: auto-tagging
i retroactively tagged all assets as "official" or "fanmade" based on:
- filename patterns (anything with "fanmade" in the name)
- specific rules (like genshin splash arts ending in "-nobg" are fanmade)
what used to be folders and filenames became this:
## the final stack
i could've 100% went with tRPC or something, however skowt has a lot of developers who rely on the API for their own projects, plus there's barely any existing oss repositories that use the stack i chose here.
and of course, deployed on cloudflare workers/pages.
### backend
- hono: for the api
- full zod openapi spec: no brainer
- scalar: for our api reference
- drizzle orm: for database queries
- better auth: handles discord auth
- turso: database
### frontend
- nextjs: web framework, it's what i know best, sadly
- redux: state sync for selecting multiple assets
- tailwind: who isn't using tailwind
- typed-openapi: api client generation from the backend openapi schema
- better auth: for the separate backend/frontend setup
### new search implementation
the new site has pretty advanced search capabilities. like, you can filter by multiple tags, games, categories, all at the same time.
the search supports:
- name search: partial matching with LIKE queries
- tag filtering: with AND logic - asset must have ALL specified tags
- game filtering: filter by multiple games
- category filtering: filter by multiple categories such as character sheets, splash art, etc.
- only allows for match searching: games must have appropiate categories, games must have appropiate games.
- sorting: view count, download count, upload date, or name
- pagination: via offset-based navigation (fetch 21 assets, check for an additional +1 from 20, if so, there's a next page.)
- combination queries: e.g. "fanmade" tag + "genshin-impact" game + "character-sheets" category
### authentication
as the site already has a discord community, and that was where all the contributors were, i decided to go with discord authentication for the site using better auth. as much as i'm more of a 'write auth yourself' guy, i decided to cheat here just to make things a little easy for myself.
this was super easy to setup. however there was one issue about better-auth: it automatically picks your discord display name as your name, which i did NOT know about.
and, in our case, "name" was mapped to to username in better-auth's config.
imagine people with the same display name, users with special characters as their display, or people w/ the same display name. it causes issues. bad ones.
luckily, better auth provides a mapProfileToUser function, so it's fixable:
## impact
- api response time: stupidly low, so far, there's been no 500s!
- search functionality: nonexistent > full-text search with complex filters
- complex queries: users can get exactly what they are looking for easily
- api documentation: auto-generated and made pretty with scalar
- less frequent caching: new assets, etc are visible almost immediately
## closing thoughts
rewriting infrastructure for a moderately popular site while keeping it running is exhausting. if anything, it's just getting over that initial fear, then it all comes naturally.
and not everything has to be perfect at first! just get what you want out into the world, then you can always improve on it, take in user feedback, etc. it's not the end of the world if something isn't perfect on your first try.
### repos
- api: github.com/skowtcc/api
- site: github.com/skowtcc/site